Hola a todos!
Este post lleva bastante tiempo en mis pendientes y lo he ido retrasando debido a unos cambios que se produjeron en los containers de wazuh para su nueva versión 2.0; ahora que ya he tenido la oportunidad de probarlo creo que va siendo hora de que os cuente algo sobre el tema.
Pero, antes de nada, creo que debería de contaros que es Wazuh. Wazuh es un HIDS (Host Intrusion Detection System) que además puede actuar como un HIPS (Host Intrusion Prevention System), inicialmente basado en un fork de Ossec; en los últimos meses se han ido desligando cada vez más del mismo y han ido incluyendo muchas más funcionalidades y otras aplicaciones de su propia cosecha ampliando las funcionalidades de Ossec considerablemente.
Este post se basa en la versión disponible, a día de hoy, de la 2.0; esta versión todavía está en fase de desarrollo e irá contando con muchas más funcionalidades en un tiempo próximo.
En su versión 2.0 Wazuh ha optado por, en lugar de utilizar un macro container con todo dentro, en separar las distintas partes del mismo para facilitar así temas como actualizaciones de una aplicación en concreto por ejemplo. Así, tendremos 4 containers: 1 para wazuh en sí (Ossec); y los 3 correspondientes a ELK (Elasticsearch, Logstash y Kibana).
Como es lógico necesitaréis tener instalado docker y, para hacerlo todo mucho más sencillo, docker-compose.
En este post os deje un pequeño script que os puede ayudar a instalar docker de manera muy sencilla. En el caso de docker-compose, aquí os dejo el link a la documentación original de como instalarlo; en mi caso, curiosamente, en algún equipo estaba disponible en los repositorios del propio docker.
Una vez tengamos ambas aplicaciones listas, necesitaremos descargar el archivo docker-compose que nos ayudará a levantar todo nuestro servidor. Este lo podremos obtener en https://github.com/wazuh/wazuh-docker . También podéis ver que existen más archivos dentro del repositorio, aunque solamente el docker-compose.yml es necesario, yo he preferido clonarlo todo para poder ver las distintas configuraciones utilizadas, así que voy a asumir que sois igual de curiosos que yo y hacemos:
git clone https://github.com/wazuh/wazuh-docker
Esto nos clonará, en el directorio actual, todo el repositorio. En caso de que no tengáis git o solamente queráis el archivo docker-compose, podéis descargarlo directamente con wget o lo que mejor os convenga de la siguiente manera:
wget https://raw.githubusercontent.com/wazuh/wazuh-docker/master/docker-compose.yml
En caso de que queramos que la información de los containers no se destruya junto con estos mismos necesitaremos crear unas carpetas que luego mapearemos (perdonad el palabro) a dichos containers y que guardaran nuestras configuraciones y demás información en nuestro sistema.
Por defecto necesitaréis 3 directorios, en mi caso cree 4, os explico porqué. Uno de los problemas que tiene Ossec es que no soporta autenticación en smtp para enviar correos así que si nuestros servidor saliente necesita de esta tendremos que configurar un relay para que Ossec, o Wazuh en este caso, pueda enviar notificaciones de correo. Para evitar tener otro container aparte yo instalé postfix en el container de Wazuh (actualmente ya viene preinstalado en la imagen) y cree una carpeta para guardar la configuración del mismo, está es totalmente opcional y no hablaré de ello en esta guía para no complicaros más la vida sino que creare un post aparte con lo pasos que seguí.
Una vez hayáis decidido donde queréis crear las carpetas, en mi caso /var, las creamos y modificamos el archivo docker-compose.yml con nuestro editor favorito; descomentamos las lineas de los volumenes y cambios my-path por el path a nuestras carpetas, en mi caso se vería así:
version: '2'
services:
wazuh:
image: wazuh/wazuh
hostname: wazuh-manager
restart: always
ports:
- "1514/udp:1514/udp"
- "1515:1515"
- "514/udp:514/udp"
- "55000:55000"
networks:
- docker_elk
volumes:
- /var/wazuh:/var/ossec/data
depends_on:
- elasticsearch
logstash:
image: wazuh/wazuh-logstash
hostname: logstash
restart: always
command: -f /etc/logstash/conf.d/logstash.conf
volumes:
- /var/logstash/config:/etc/logstash/conf.d
links:
- kibana
- elasticsearch
ports:
- "5000:5000"
networks:
- docker_elk
depends_on:
- elasticsearch
environment:
- LS_HEAP_SIZE=2048m
elasticsearch:
image: elasticsearch:5.2.2
hostname: elasticsearch
restart: always
command: elasticsearch -E node.name="node-1" -E cluster.name="wazuh" -E network.host=0.0.0.0
ports:
- "9200:9200"
- "9300:9300"
environment:
ES_JAVA_OPTS: "-Xms2g -Xmx2g"
volumes:
- /var/elasticsearch:/usr/share/elasticsearch/data
networks:
- docker_elk
kibana:
image: wazuh/wazuh-kibana
hostname: kibana
restart: always
ports:
- "5601:5601"
networks:
- docker_elk
depends_on:
- elasticsearch
entrypoint: sh wait-for-it.sh elasticsearch
networks:
docker_elk:
driver: bridge
ipam:
config:
- subnet: 172.25.0.0/24
Probablemente os habréis fijado que en el caso de logstash yo he creado un subdirectorio llamado config dentro de la carpeta de logstash, esto es preferencia mía simplemente.
Antes de iniciar nada, debemos modificar un parámetro con sysctl para aumentar la cantidad de memoria virtual que se puede reservar ya que sino logstash se quejará de que no tiene suficiente memoria:
sysctl -w vm.max_map_count=262144
Con esto ya deberíamos tener todo listo para arrancar, utilizaremos la opción «-d» para enviarlos a segundo plano ya que sino lanzaran todos sus logs por pantalla y será dificil hacer cualquier tipo de debug:
docker-compose up -d
Este comando, y sus derivados como stop o down, debe ser lanzado siempre en la misma carpeta del docker-compose.yml, ya que al igual que con docker build, este automáticamente busca este archivo.
Los containers arrancaran todos a la vez pero tanto el de logstash como el de kibana esperaran de forma interna a que elasticsearch este funcionando para terminar de iniciar. Podéis comprobar los logs de cada uno utilizando el siguiente comando:
docker logs wazuhdocker_<app>_1
Donde app será una de las 4 aplicaciones: wazuh, logstash, elasticsearch o kibana.
Si todo ha salido bien podremos acceder a kibana en el puerto 5601 de nuestro servidor de docker. El siguiente paso será añadir agentes al mismo.
Tanto Wazuh como Ossec soportan recibir información de agentes tanto con o sin su agente instalado, el segundo caso solo suele ser recomendable en casos donde no podemos instalar el cliente, bien sea por permisos, bien sea porque no es posible hacerlo, un router por ejemplo. No suele ser recomendable porque en ese caso perderíamos la oportunidad de utilizar las opciones de IPS al no poder ejecutar comandos en el agente ni administrarlo de forma remota, por ejemplo: tenemos un router con OpenWRT, al no tener agente para este SO hacemos que syslog envíe la información al servidor de Wazuh directamente; esta se procesará igual que las de un agente normal pero en caso de intrusión no se ejecutara ninguno de los scripts de respuesta activa para prevenirlo.
Podéis encontrar los agentes para distintas plataformas en este link. Una vez instalado el agente tenemos que registrarlo en el servidor para que pueda comunicarse con el mismo. Para esto existen dos métodos: manual o utilizando ossec-authd. Para empezar yo prefiero el primer método, aunque pueda parecer engorroso al principio creo que es el mejor para ir viendo como funcionan los diferentes scripts de Wazuh. Existe un conflicto entre el método manual y ossec-authd que hace que no podamos registrar un nuevo cliente si tenemos el segundo funcionando a la vez, para evitar esto vamos a matar dicho proceso; primero nos conseguimos shell en el container de wazuh:
docker exec -it wazuhdocker_wazuh_1 /bin/bash
Utilizamos ps para localizar el PID del proceso de ossec-authd:
ps aux | grep ossec-authd
Y procedemos a terminarlo con kill, en mi caso el PID era el número 11:
kill 11
Volvemos a comprobar con el anterior comando de ps que el proceso ha desaparecido y seguimos con el proceso de registro. El script en cuestión lo podremos ejecutar ya en la shell que tenemos ahora mismo abierta o, para no andar abriendo shells cada vez que queramos registrar un nuevo agente, utilizaremos el siguiente comando:
docker exec -it wazuhdocker_wazuh_1 /var/ossec/bin/manage_agents
Igualmente podemos ejecutar dicho comando en la shell, este nos devolverá un menú. Seleccionamos la opción «A» para añadir un nuevo agente, y cubrimos los datos que nos pide; el ID podéis dejar el que os da ya que es autoincremental, a no ser que queráis especificar uno en concreto.
Una vez finalizado el registro del agente nos devolverá al menú inicial, ahora debemos seleccionar la opción «E» para obtener la llave que le pasaremos a nuestro agente. El script nos mostrara todos los clientes registrados y debemos introducir el ID del que nos interesa; esto nos devolverá un string codificado en base64 que deberemos copiar para pasarselo a nuestro agente.
Ahora nos vamos al servidor donde hayamos instalado el agente, solo he probado los agentes de linux y windows así que me limitaré a estos:
Linux:
Ejecutamos el siguiente comando:
/var/ossec/bin/manage_agents
Veréis que es exactamente el mismo script que hemos utilizando en el manager para añadir los clientes, tanto el agente como el manager se instalan ambos en el mismo directorio; en este caso solo se nos muestra una opción aparte de la de exit y es importar la key que copiamos anteriormente, seleccionamos la opción «I» y copiamos la key. Reiniciamos el cliente para que se apliquen los cambios:
/etc/init.d/wazuh-agent restart
Si todo ha ido bien podremos ver el agente conectado en kibana.
Windows:
En el cliente de windows quizás es mucho más sencillo, simplemente debemos copiar la en el campo Authentication Key como se muestra en la siguiente imagen:
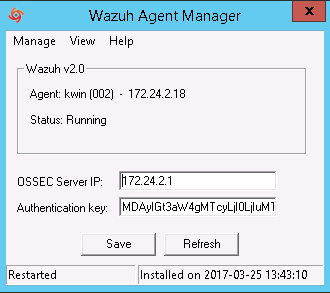
También debemos especificar la dirección del servidor de Wazuh/Ossec, hacemos click en save y veremos como se actualiza la información del campo Agent.
Reiniciamos el cliente haciendo click en manage-> restart:
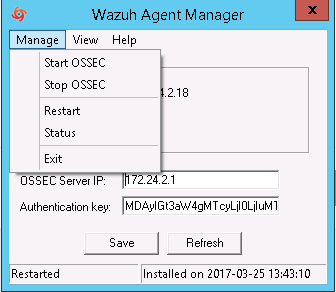
Si todo ha ido bien veremos el agente en kibana.
Una vez hayamos conseguido añadir algunos agentes ya podremos comenzar a ver información en kibana y disfrutar de los diferentes dashboards que la gente de Wazuh ha preparado para nosotros. Ya tenéis un HIDS totalmente funcional.
Como nota importante comentaros que si actualizais el container muy probablemente los cambios que hayáis hechos en la configuración volveran a default, por defecto Wazuh genera un backup de vuestra configuración antigua así que no os tenéis que preocupar de perderla. En el caso de las reglas, la best practice, y para no perder los cambios ya que estos archivos no se tocan en los updates; será añadirlos a los archivos local_rules.xml o local_decoder.xml localizados en /var/ossec/etc/ en las carpetas rules y decoders. Pero sobre esto hablaré en futuros post.
En caso de que tengáis algún problema los logs de ossec se guardan por defecto, tanto para el manager como para los agentes, en la carpeta /var/ossec/logs; recordad que en el caso del manager, al haber mapeado dicha carpeta, podéis acceder directamente a la carpeta logs en el path que le hayáis especificado sin tener que conectaros al container.
Con esto ya tendríais una instalación básica pero funcional de Wazuh y podéis empezar a familiarizaros con su interfaz de kibana y ver las distintas opciones que nos ofrece, Wazuh nos ofrece muchas más posibilidades como añadir checks de OpenSCAP a nuestros agentes, notificaciones de correo, despliegue de configuración remota a los agentes, ejecución de scripts en remoto, y un largo etc. Pero eso serán cosas para otro post.
Espero que os haya gustado el post y os sea útil, para cualquier duda podéis dejarme un comentario aquí y os animo a pasaros por la lista de correo de Wazuh:
[email protected]
Saludos, y como siempre, gracias por vuestra visita!

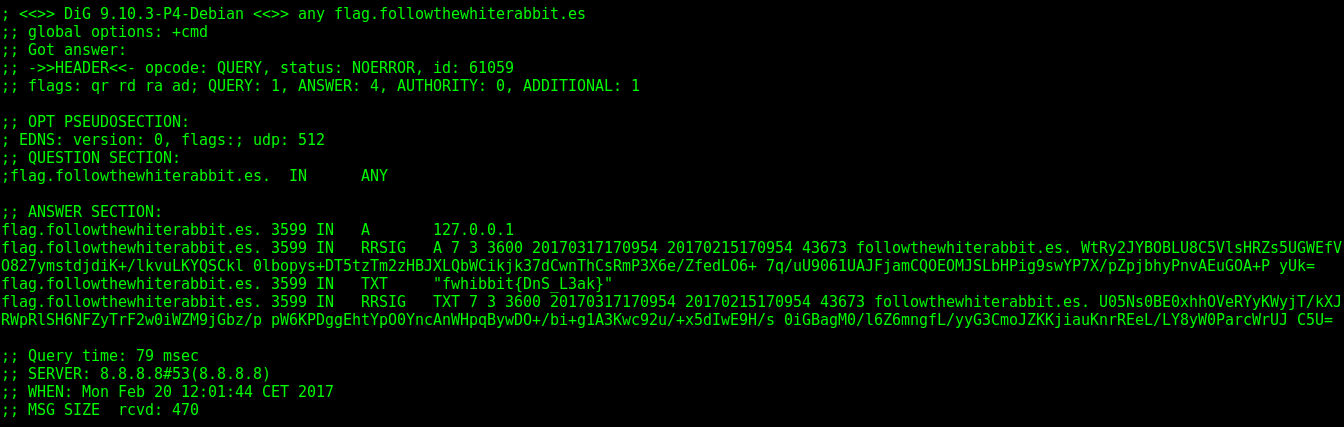
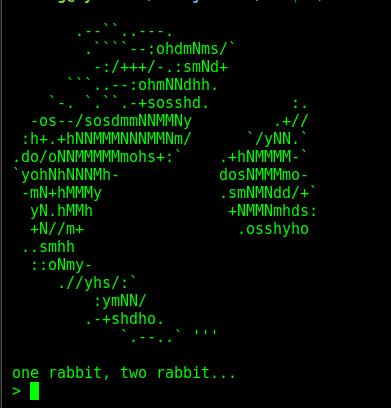
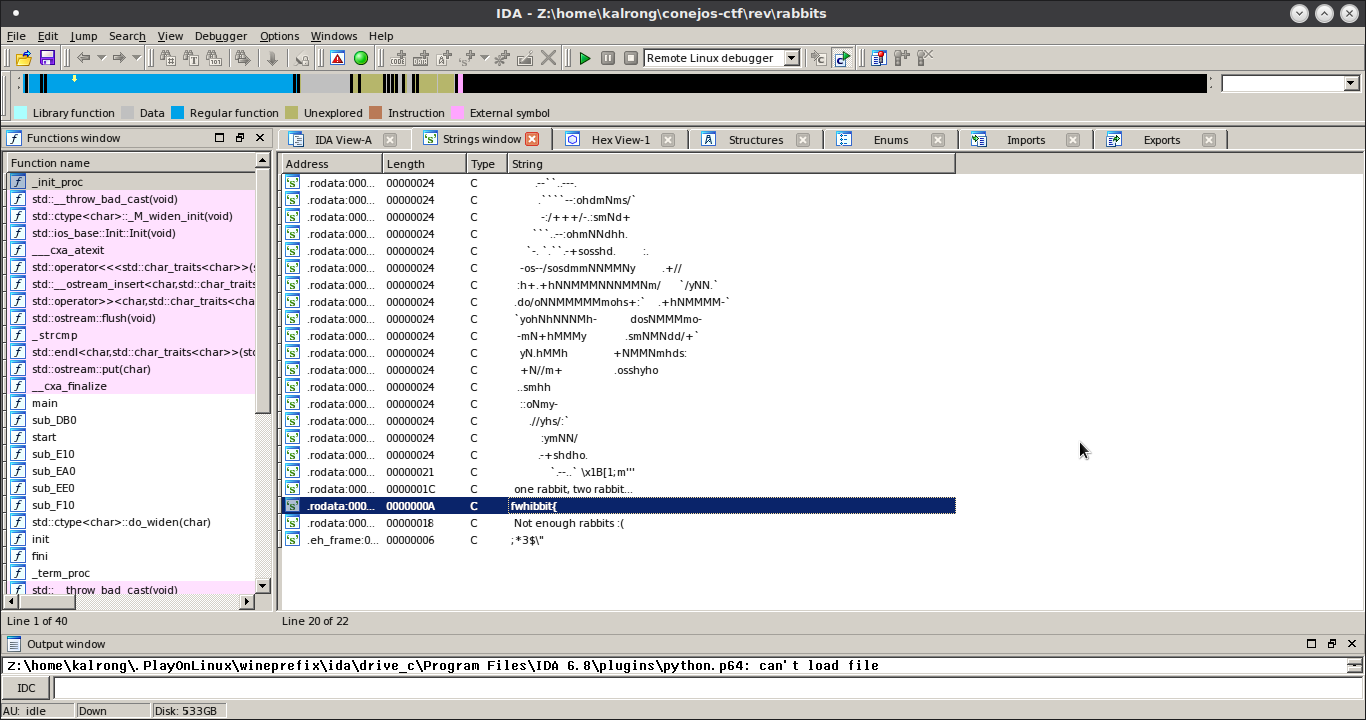
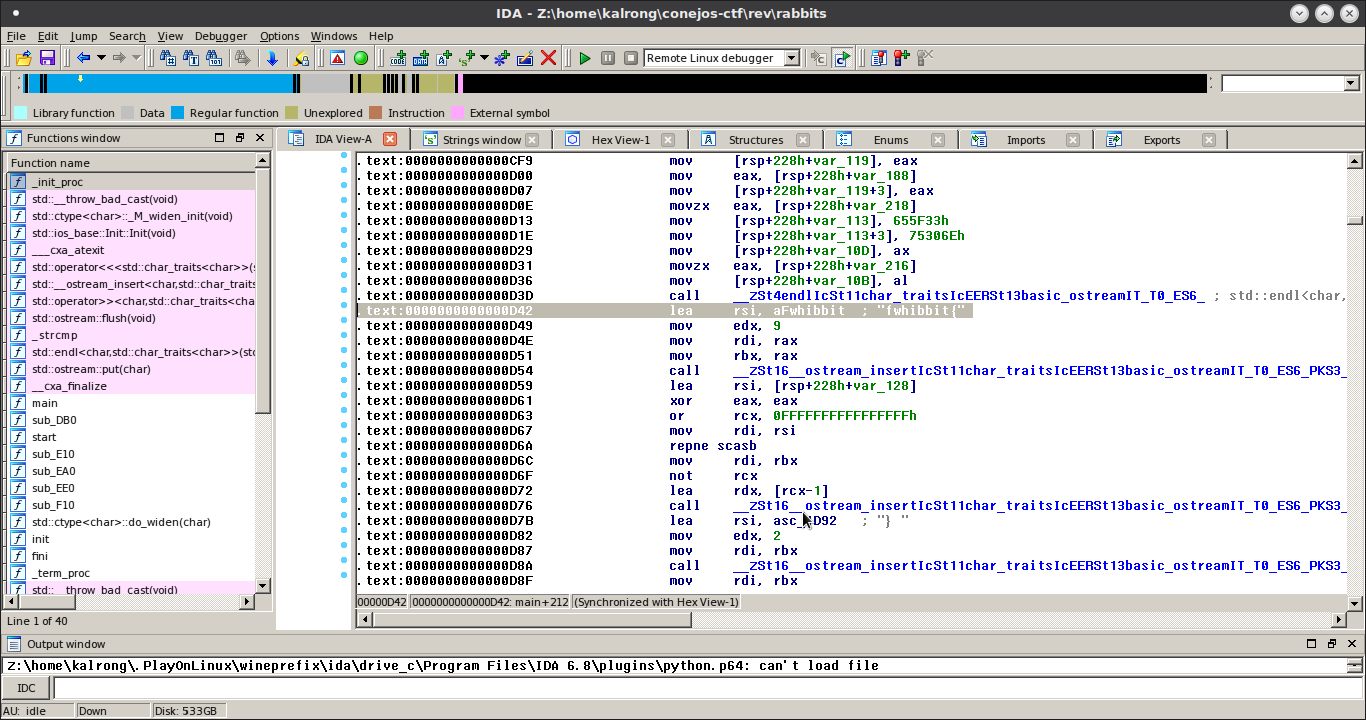
 Y nada más…, pero esto que es! Por lo menos hubiera dejado un mensaje diciendo algo sobre ella. Porque supongo que esta imagen, así sola, no significa nada no?
Y nada más…, pero esto que es! Por lo menos hubiera dejado un mensaje diciendo algo sobre ella. Porque supongo que esta imagen, así sola, no significa nada no?